I tested 5 ML algorithms across 7 datasets. The "best" one didn't exist.
A year-long master's thesis, a Python benchmarking tool, and seven evaluation metrics. The lesson wasn't which algorithm wins — it was why the question is wrong.
I tested 5 ML algorithms across 7 datasets. The “best” one didn’t exist.
Every machine learning tutorial gives you the same advice: “Try Random Forest first.”
I followed that advice for years. Then I spent a year building a tool to test it properly — and the answer turned out to be uncomfortable.
The setup
For my master’s thesis, co-supervised between the University of Maribor and UPC Barcelona, I built a Python tool that benchmarks five classification algorithms — Logistic Regression, Decision Tree, Random Forest, SVM, and KNN — across seven datasets, scoring each on seven metrics (Accuracy, Precision, Recall, F1, Cohen’s Kappa, Hamming Loss, Jaccard) plus training and prediction time.
I expected a clear winner. I didn’t get one.
What actually happened
- On Iris and Digits, every algorithm performed beautifully. Pick any one.
- On Wine and Breast Cancer, Logistic Regression and Random Forest dominated; SVM and KNN trailed badly.
- On Olivetti Faces, SVM jumped to the front.
- On Covertype, KNN was the best — the same KNN that was nearly the worst elsewhere. SVM, the hero of the previous dataset, collapsed.
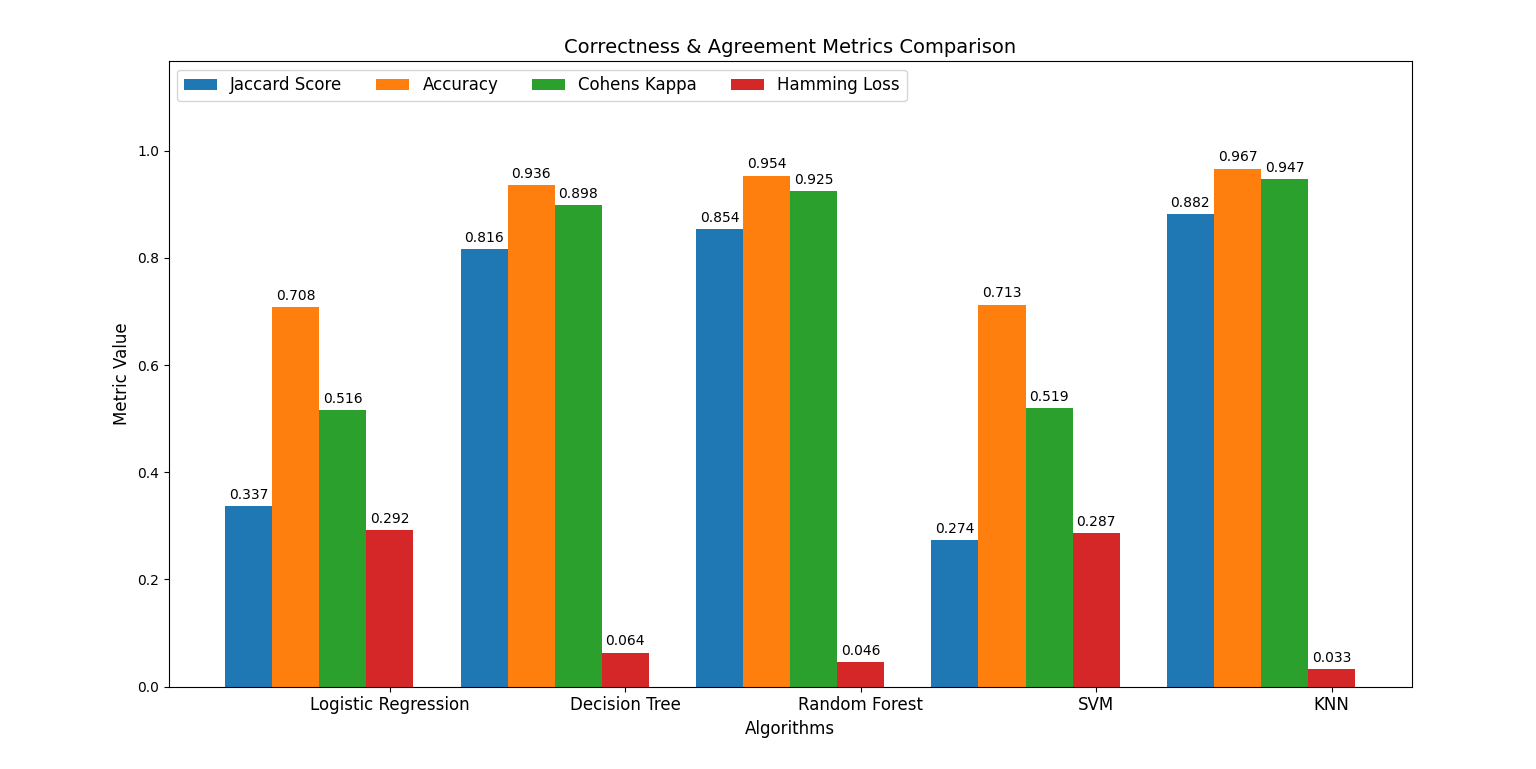
If I’d run this thesis on three of those datasets, I would have left convinced Random Forest was the answer. On the other four, I’d have walked away convinced of something completely different.
Why this actually matters
We talk about ML algorithms like they have personalities — “use this one for X, this one for Y.” But the dataset has the personality. Algorithm choice is a conversation between the math and the data in front of you, not a rule you memorize once from a blog post.
In production, this means: the “best” model is the one you measured on your own data. Cheap, tedious benchmarking beats expensive reasoning from authority.
There’s a second layer the metrics taught me. Accuracy and F1 don’t always agree. Cohen’s Kappa can flag a model that’s beating random chance by a hair while accuracy says it’s “great.” A model can win on one metric and lose on every other measure that actually matters for an imbalanced dataset. You don’t know which metric matters until you know what a wrong prediction costs you.
What it taught me
Build the thing that measures, not the thing that argues. The tool I shipped was simpler than any of the algorithms it tested — and it answered the question better than any blog post could.
Also: track time, not just accuracy. A model that’s 1% more accurate and 10× slower to train is the wrong choice more often than people admit.
The real takeaway, looking back: the discipline of measuring is more valuable than the model you measure.
If you want the full version — methodology, all seven datasets, every chart, the comparison tool — the full master’s thesis is open access on UPCommons.
What’s your default algorithm when you start a new classification problem? Curious where the consensus sits today.
#MachineLearning #DataScience #Python #ScikitLearn #MastersThesis #PredictiveAnalytics #Classification