Where do you put JSON? I benchmarked three databases to find out.
My bachelor's thesis pitted MySQL, PostgreSQL, and MongoDB against 100,000 JSON documents. The interesting question wasn't which won — it was where each one broke.
Where do you put JSON? I benchmarked three databases to find out.
If you’ve worked on a backend in the last decade, you’ve had this argument:
“Just put it in Mongo.” “No, modern Postgres handles JSON fine.” “MySQL has JSON columns now too.”
For my bachelor’s thesis, I tried to settle it — with a stopwatch and a memory profiler instead of opinions.
The setup
I built an automated benchmarking app in Python that ran the same CRUD workload (insert, read, update, delete) against MySQL, PostgreSQL, and MongoDB. Two scenarios: a small JSON document and a large one. Volumes scaled up to 100,000 records. PyMongo, Psycopg, and MySQL Connector did the talking; Python’s standard time library kept score.
The goal wasn’t to declare a winner. It was to find where each one breaks.
What broke first
- MySQL was fine on small data. The moment documents got large and volumes grew, both speed and memory degraded fast. Both axes failed it simultaneously.
- PostgreSQL held up far better than I expected. It was fastest on insert by a wide margin, came out on top in several other operations too, and tracked MongoDB on memory at every scale. The lazy “modern Postgres handles JSON fine” take turned out to be largely true.
- MongoDB still won the most consistent overall story — strong on most operations and the lowest memory footprint at 100,000 documents. But the clear margin was against MySQL, not PostgreSQL: against Postgres the gaps were often slim. The trick is BSON: storing JSON as binary means it never has to parse the document just to read a field.
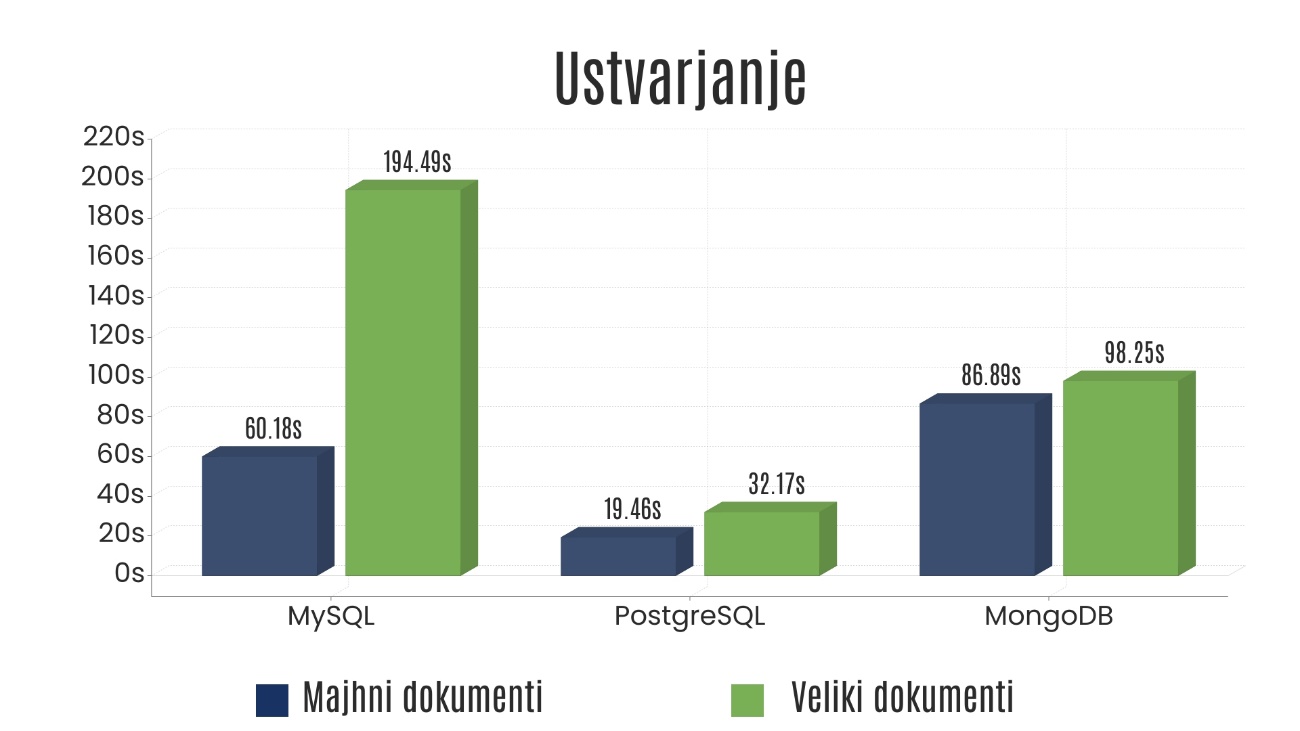
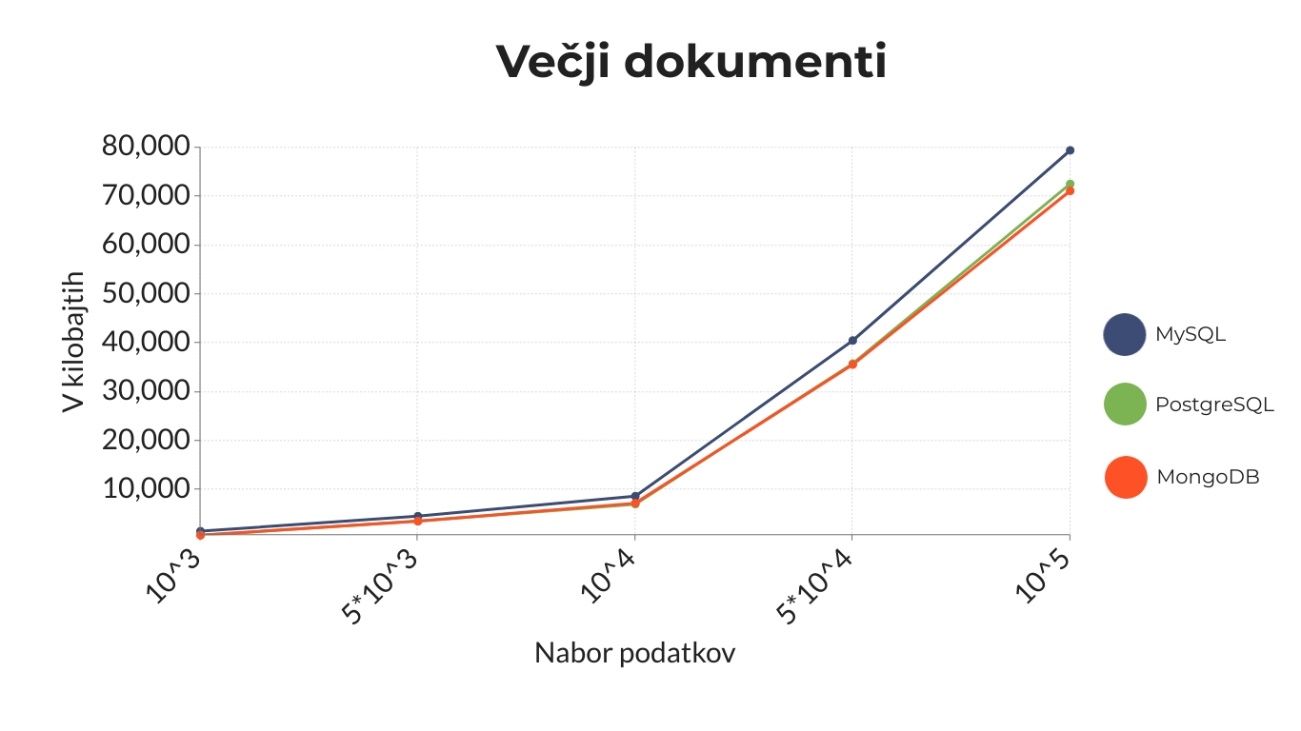
The narrative “SQL vs NoSQL” wasn’t the useful one. PostgreSQL tracked MongoDB on most metrics; MySQL was the clear outlier.
Why this still matters
JSON-shaped data is now everywhere — APIs, events, logs, user-generated content. Where you put it is a five-year cost decision: latency compounds across millions of requests, and memory bills compound faster.
If you’re picking a database for JSON-heavy workloads today, this is the test I’d run before reading another comparison article: pull 100,000 representative documents from your real domain, time the four basic operations, watch the memory curve, and let the numbers argue.
What it taught me
Three things I still use every week:
- Measure your own workload. Generic benchmarks lie to you in the only direction that matters.
- The interesting question is “where does it break?” — not “which is fastest?” Breaking points are what your future on-call self will thank you for knowing.
- Binary beats text for anything you’ll write more than you’ll read by hand.
This was my first real engineering project. Five years later, the specific numbers are obsolete — but the lens it gave me, measure first, opinions later, is still how I make every infrastructure call.
If you want the full version — methodology, every chart, the testing app, the raw measurements — the full bachelor’s thesis is archived at the University of Maribor (in Slovenian).
What’s your default for JSON-heavy workloads today, and what would actually change your mind?
#MongoDB #PostgreSQL #MySQL #NoSQL #DatabaseDesign #BackendEngineering #JSON